Implementing API Pagination in Clockspring: A Step-by-Step Guide
Scenario:
APIs often limit the amount of data returned from a single call by paginated results. This can create challenges if you needed to pull in 10,000 records but each response only returns 100 for each request. In this scenario Clockspring needs to loop through the paginated results by identifying the url for the subsequent page as well as identify when it has reached the last page to break the loop.
Solution:
Paginated responses will return the payload data along with the path to the next page in the response. We must split these data streams apart by forking the flow into two phases. The first will extract the next page identifier, determine if there are more pages to query, then execute the API call to retrieve that data. The other phase will route the payload data to the section of the flow responsible for processing it.
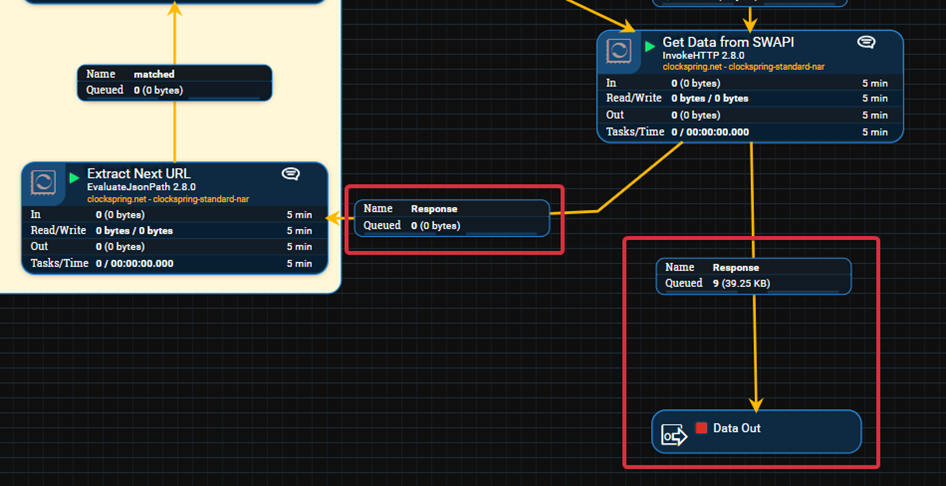
While this concept is not overly complex, it can be helpful to see an example of a finished data flow before examining the details:

This flow consists of 4 processors to perform those steps. In this example we are using data from the Star Wars API (SWAPI) at https://swapi.dev/api/people which returns 10 results per call in JSON format.
Calls to this endpoint return with the format:
{
"count" : 82,
"next" : "https://swapi.dev/api/people/?page=2",
"previous" : null,
"results" : [ {
"name" : "Luke Skywalker",
"height" : "172",
--snip--
}| count | The total number of records associated with the ‘people’ resource |
|---|---|
| next | The URL for the next page of results |
| previous | The URL for the previous page of results |
| results | An array containing the actual data we are hoping to retrieve |
The final page sets the value of next to null when there are no more pages left to retrieve:
{
"count" : 82,
"next" : null,
"previous" : "https://swapi.dev/api/people/?page=8",
--snip--
}
This allows us to easily identify the resource to fetch the next page results as well as identify when we are at the final page. Now we just need to extract the next URL from the returned content, determine if it's populated, and if so reach out to that page.
To do this we extract the next URL using the EvaluateJsonPath processor. This processor uses the JSONPath query language to match an element within the JSON structure. In our case we want the $.next element to be stored and we are going to store that as the attribute named url.
Now that we have a url attribute with the value of the next page we need to validate that this value is not null. The RouteOnAttribute processor can be used to accomplish this. Configure the processor with a new dynamic property with the property name set to the new relationship name you'd like to use. For the value we will use the Clockspring expression language called isEmpty against that url attribute.
${url:isEmpty()}
With this configuration the processor will send any FlowFiles with an empty url attribute to the lastPage relationship. If this attribute is NOT empty it will send it down the unmatched relationship and sent back to InvokeHTTP to fetch the next page of results. Note: In a production environment the lastPage relationship would likely be terminated, but it was left in this example for illustrative purposes.
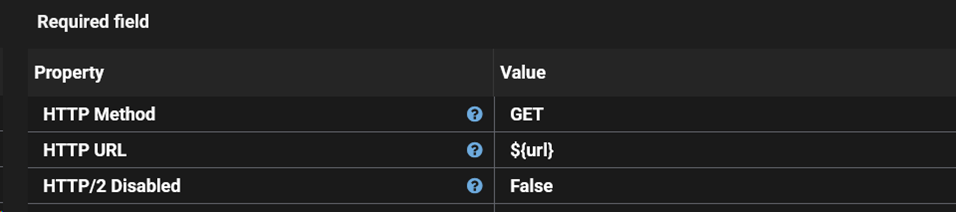
This does complicate our first call though. When the flow is first started, how is Clockspring going to know what the initial url attribute value is? That's where the initial GenerateFlowFile comes in at the top of the screen. GenerateFlowFile allows us to define the initial value of attributes. In this case we will populate with the initial value the url to https://swapi.dev/api/people.
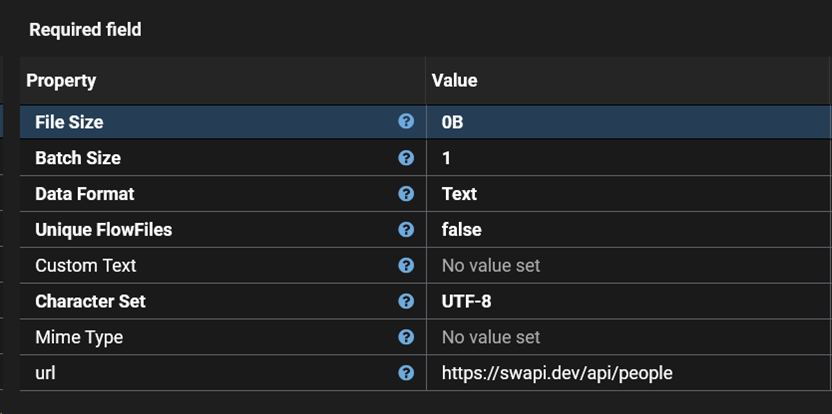
Now that we have a loop to iterate through all of the pages we can start processing the result data.
In this example we connected a second Response relationship after the InvokeHTTP processor to route the data to that processing function. After executing this flow and letting it run to completion you should see 9 files in that response queue which contain the data from the 9 pages returned by the SWAPI people endpoint.
Summary:
As a recap to what was completed in the steps above:
This loop is provided using the following 4 processors:
GenerateFlowFile - Create the initial FlowFile with the ${url} attribute set to the first page
InvokeHTTP – Execute an HTTP GET request to ${url} and route the results to the EvaluateJsonPath processor as well as the Output Port
EvaluateJsonPath - Extract the value of next from the returned JSON as ${url} (overwriting our previous ${url} value)
RouteOnAttribute - Determine if there is a next page and route the result appropriately.
While there are varying ways APIs could provide information around first, next, and last pages this concept can apply to many of those different methods.